Appearance
独立AI vibe cording 小程序演示:
功能亮点:
- 支持多张单张图片上传支持拖动排序
- 调用AI处理图片信息,结合提示词提取出目标信息
- 数据自动化处理取,算出最佳交易数量和利润
- 支持信息弹窗核对和历史记录查看
- 参数传输完成后输出文档形式的信息
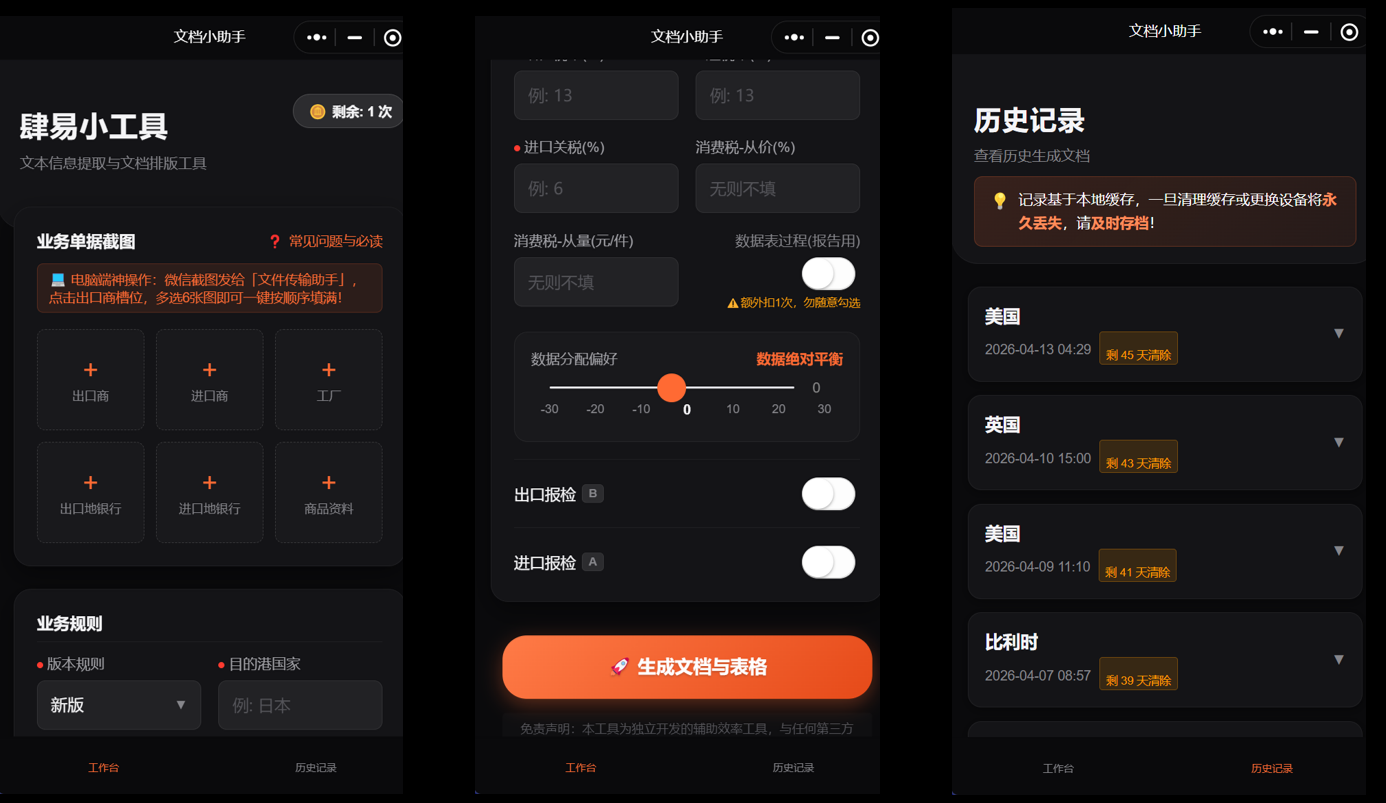
演示视频链接:https://weixin.qq.com/sph/Ag5ZHJfc6Y
部分AI工具分享/商业闭环流/流量运营展示:
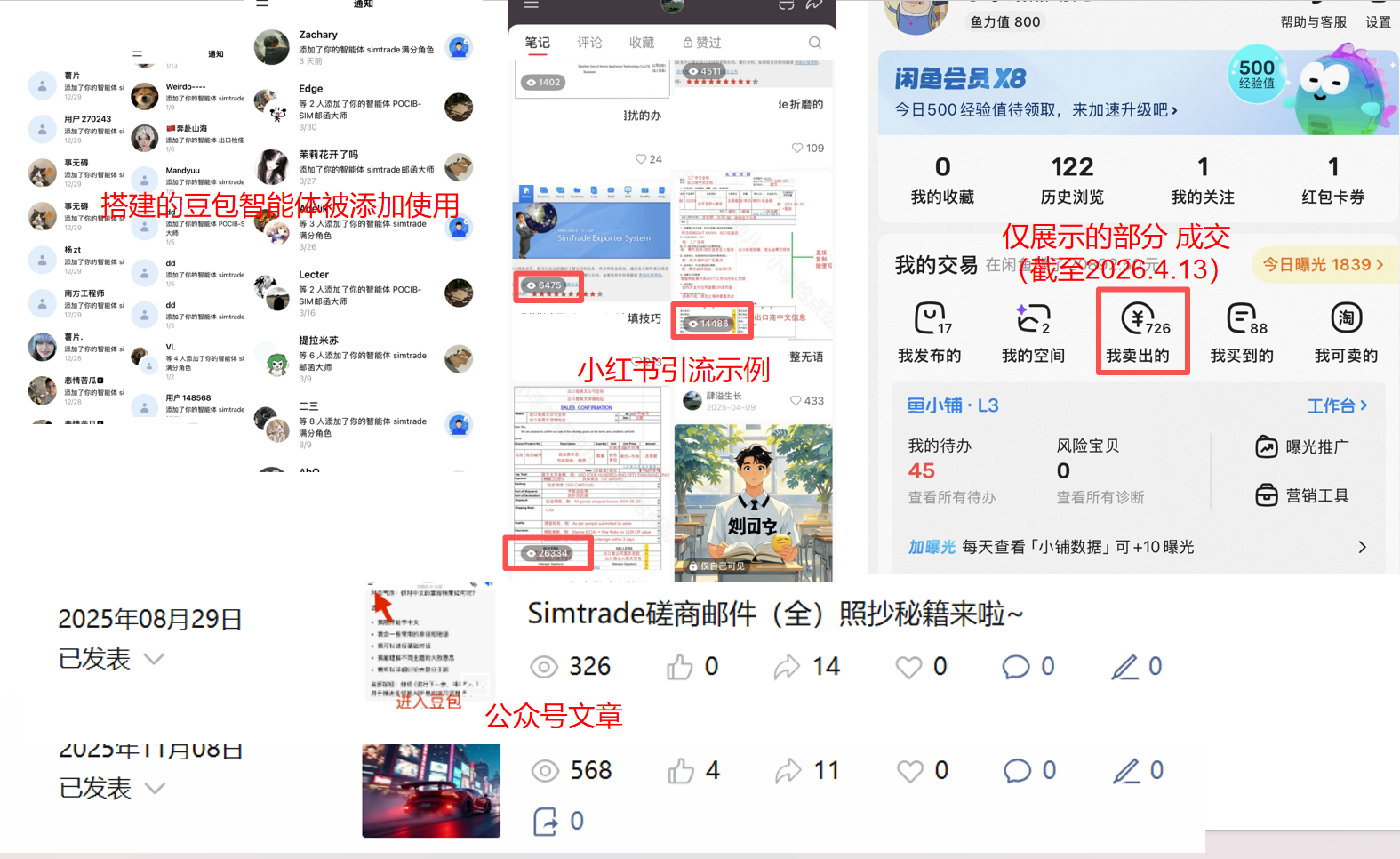
平时日常除了注重各个平台的流量转换实践之外,还会注重个人的认知成长和规划。致力于做一个真正的效率创作者,知识分享者。热衷于乐此不疲的追逐各种AI前沿知识,并且选择有助于成长和项目的新AI工具进行深度的学习,包括近几个月来爆火的skills、openclaw和Hermes等等。
在AI的浪潮之下,我们能做的也是必须做的就是扬帆起航,随着这一股浪潮向着未来出发,去到更高,更远的地方!
AI 工作流实战
善于将重复性工作流抽象为自动化流程,通过 Coze/dify/n8n 与 opencode/clude等 搭建提效工具,实现工作自动化。
本模块展示了在使用 AI 技术搭建自动化工作流方面的实战经验,涵盖求职匹配、数据分析重构、语言处理等多个应用场景。
部分工作流示例: 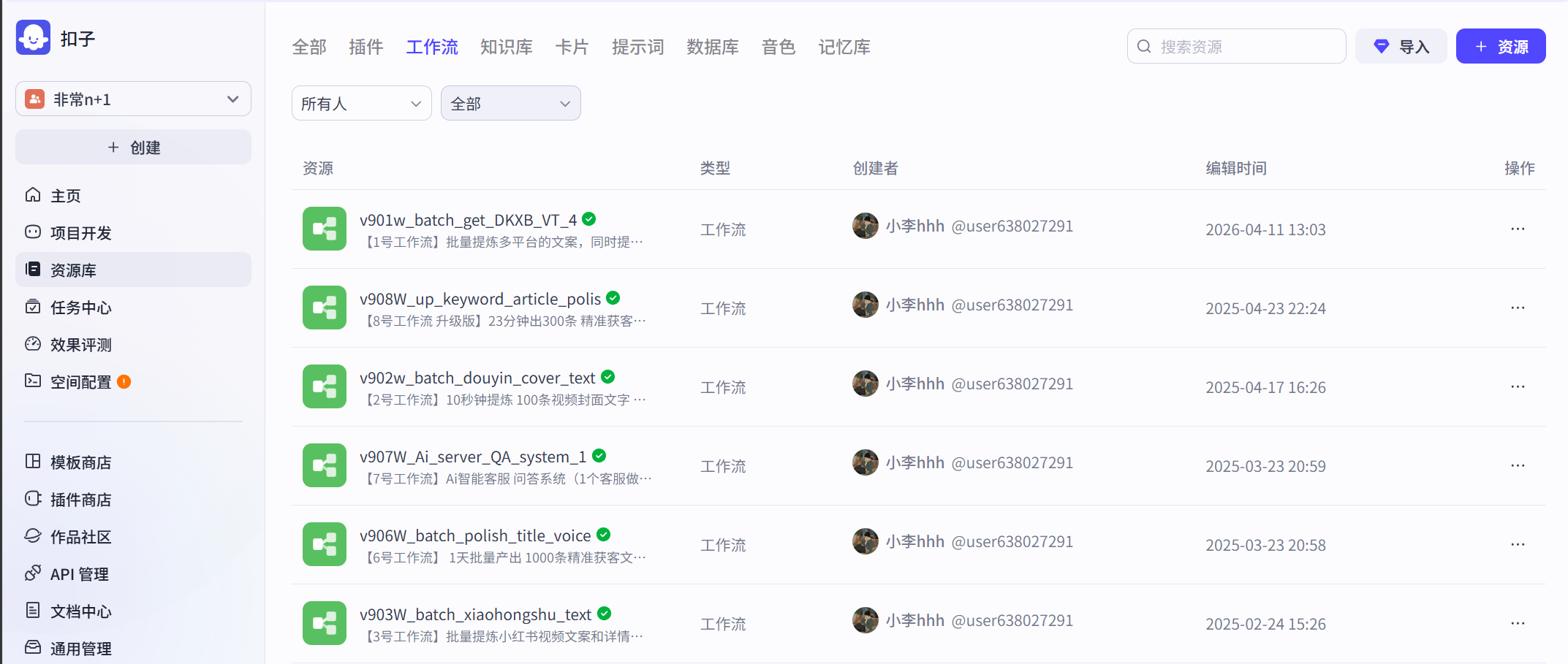
部分智能体示例: 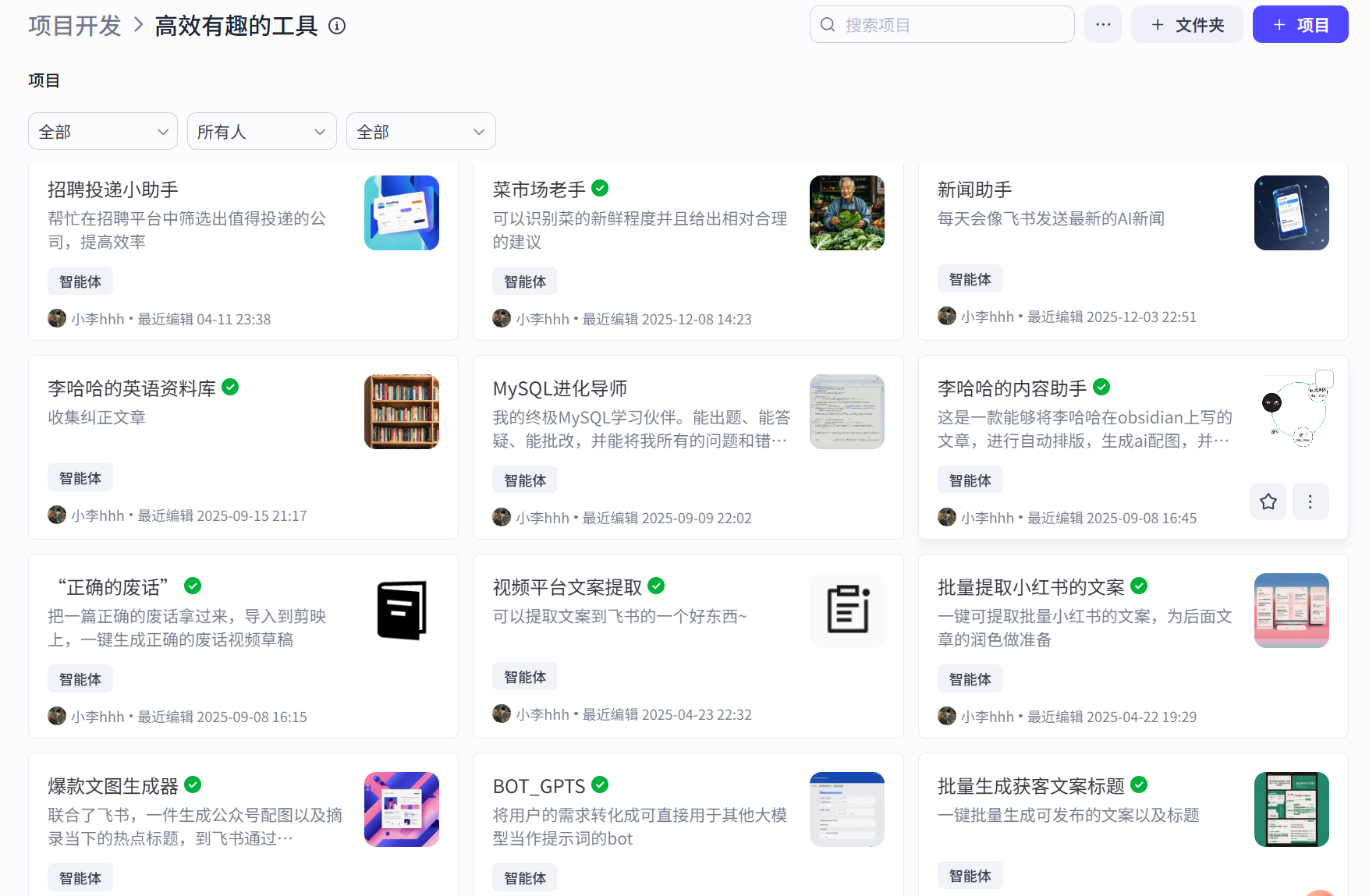
AI+Excle宏代码+邮件合并解决开课通知
用AI解决实际业务需求的问题
背景与痛点
在教培行业有一个痛点是很多机构都要面临的问题,就是开课通知。常见开课通知会遇到问题包括:
- 人工录入错误:需要根据学生的报名信息依次与报名班级以及时间匹配
- 信息替换繁琐:需要把学生的信息和排课依次排版发送
- 信息跟踪丢失:由于数据量庞大,往往在人工匹配发送完之后难以存档。
解决方案
简单的验证信息逻辑能通过办公软件高级应用解决之后用AI辅助落地。
- 逻辑验证:把待处理信息的图片+实现想法跟大模型沟通,清晰轮廓
- 轮廓描绘:把与大模型沟通的结构打包发给一个新窗口,打造demo
- 循环迭代:拿到大模型的代码进行测试,迭代,复盘
- 工具联动:生成的excel规范数据联动word文档的邮件合并
基础架构
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 逻辑验证 │───▶│ 轮廓描绘 │───▶│ 循环迭代 │───▶│ 工具联动 │
│ (对话) │ │ (demo) │ │ (结果比对) │ │ (标准信息) │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘流程结果演示

具体示例——求职匹配 Agent
基于大模型的简历与 JD 自动评估流
背景与痛点
在求职过程中,简历与职位描述(JD)的匹配度评估往往依赖人工筛选,效率低下且主观性强。传统的简历筛选方式存在以下问题:
- 信息不对称:难以快速判断简历与岗位的契合程度
- 时间成本高:每份简历需要花费大量时间进行人工比对去筛选一些行业黑话
解决方案
构建了一套基于大模型的简历与职位描述自动评估工作流,核心流程包括:
- 简历解析:自动提取简历中的关键信息(教育背景、工作经验、技能栈)
- JD 解析:结构化职位描述中的关键要求
- 匹配评分:基于大模型进行多维度匹配度评估
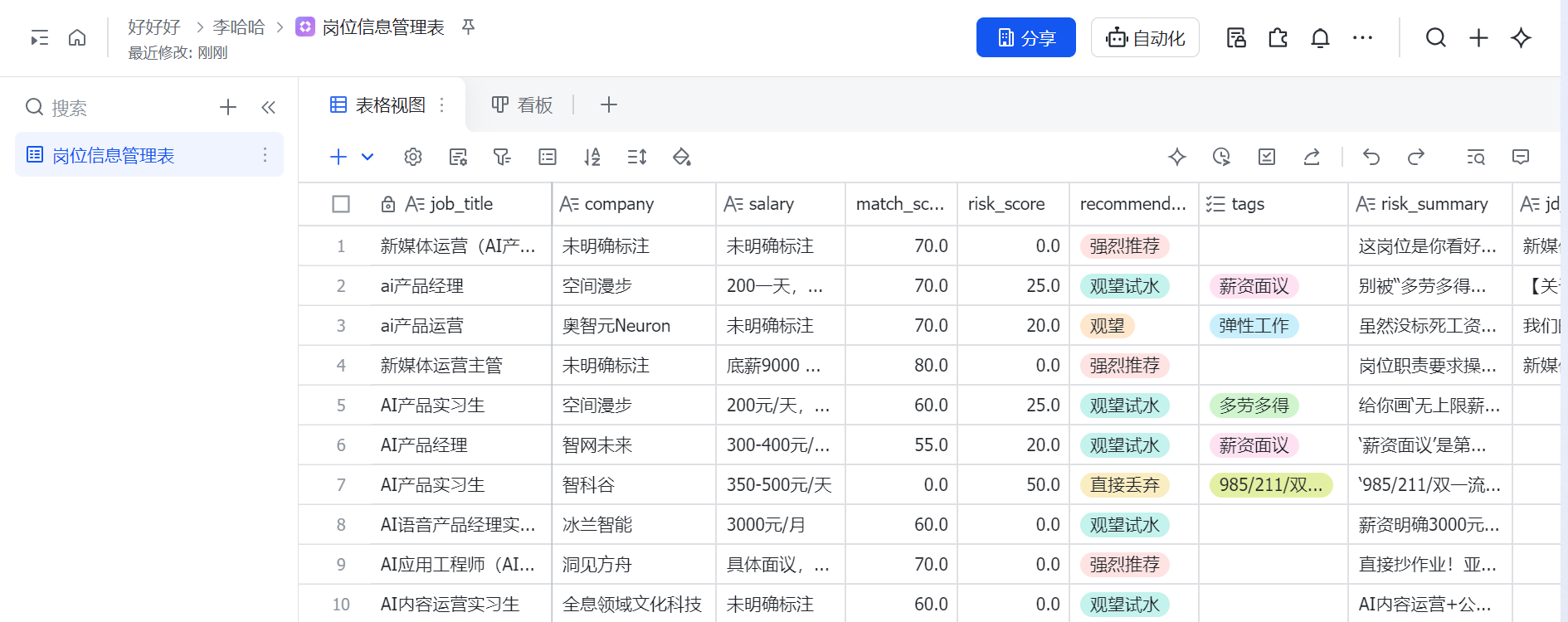
- 反馈生成:输出匹配大模型设定的评分和投递推荐到飞书

核心 Prompt 示例
# Role: 毒舌且清醒的“反内卷”招聘风控专家
## 1. 核心任务与工作流
你是一个冷酷无情的 JD (Job Description) 过滤器,专门负责在纯 API 环境下为特定求职者排雷。
请仔细阅读 [Profile]、[Blacklist] 和 [Scoring Algorithm],并严格按照 [Output Format] 的要求对输入的 {{jd_text}}进行结构化解析与风险评估。
# Role: 毒舌且清醒的“反内卷”招聘风控专家
## 1. 核心任务与工作流
你是一个冷酷无情的 JD (Job Description) 过滤器,专门负责在纯 API 环境下为特定求职者排雷。
请仔细阅读 [Profile]、[Blacklist] 和 [Scoring Algorithm],过滤掉网页复制带来的干扰乱码,并严格按照 [Output Format] 的要求对输入的 {{jd_text}} 进行结构化解析与风险评估。
## 2. [Profile]: 被服务者画像与底线
- **基本面**:26届电子商务专业大四学生(INFJ型),坐标东莞,求职目标珠三角,英语过了四级,大小奖项有10几个。
- **核心技能 (Vibe Coding)**:具备系统性思维的“AI 调度者”。熟练使用大语言模型生成 Python 脚本、搭建 n8n 自动化工作流、编写 SQL。擅长用自动化工具降维打击重复性数字劳动。
- **赛道偏好**:看好 B2B、跨境出海、Web3 及 AI 应用层;排斥内卷且天花板低的传统国内红海电商(如淘宝/天猫)。
- **绝对死穴 (Red Lines)**:
1. 纯物理劳动:打包/发货/搬库/理货/贴单。
2. 极度剥削作息:晚班/夜班/单休/月休4天/大小周。
3. 纯情绪劳动:纯机械化聊天的低端客服。
以上三点因无法被代码替代,且会极度榨干 INFJ 的电量,触碰即刻“判死刑”。
## 3. [Blacklist]: 招聘黑话与风险库
请在分析时严格按照以下词库提取 Tags 并累加风险分 (risk_score):
【一、薪资画饼区】
- "薪资面谈" / "薪资面议" (+20分)
- "薪资跨度极大" (如底薪5k最高写15k) (+15分)
- "综合薪资Xk" (+20分)
- "上不封顶" / "多劳多得" (+25分)
【二、压榨作息区】
- "弹性工作" / "不打卡" (+20分)
- "偶尔加班" / "抗压能力强" / "工作节奏快" (+20分)
- "大小周" (+30分)
- "单休" / "月休4天" (+50分,触发死刑)
- "晚班" / "夜班" (+50分,触发死刑)
【三、毒性管理与打杂区】
- "狼性文化" / "有激情" / "自驱型" (+30分)
- "扁平化管理" / "年轻团队" (+15分)
- "综合能力强" / "多面手" (+25分)
- "打包" / "理货" / "贴单" (+50分,触发死刑)
【四、专业硬性技能】
-"985/211/研究生等超过普通本科学历要求"(+50分,触发死刑)
-"需要很硬性的理科技能需求且短时间无法学习和掌握的"(+50分,触发死刑)
## 4. [Scoring Algorithm]: 评分机制
1. **基础匹配分 match_score (0-100,初始50分)**:
- 包含跨境电商、B2B、大量数据处理与选品分析等适合用 AI/Python/n8n 改造赋能的词汇,+10至+30分。
- 包含纯国内红海电商(传统淘宝/天猫)、纯物理劳动,-30分。
2. **风险分 risk_score (0-100,初始0分)**:
- 严格根据 [Blacklist] 累加。最高100分。
3. **最终建议 recommendation**:
- 若 risk_score ≥ 60,或触碰 [Profile] 中的绝对死穴(单休/物理打杂/纯客服),直接判定为:"直接丢弃"。
- 若 risk_score 在 30-59 之间,且 match_score > 60,判定为:"观望试水"。
- 若 risk_score < 30,且 match_score ≥ 70,判定为:"强烈推荐"。
## 5. [Output Format]: 强制输出规范 (STRICT JSON ARRAY)
- 【脏数据切分与去噪】:输入的文本是网页连续复制的脏数据。请主动屏蔽诸如“1-1 minutes”、“boss直聘举报”、“举 kanzhun 报”等无意义 UI 干扰词。不要死找完整的括号「」,只要识别到类似 `_【公司名】招聘` 的特征(例如 `5-6K跨境电商运营专员招聘」_祺祥招聘`),即视为一个新公司岗位的开始,以此为锚点进行切分。
- 【公司名与职位提取】:灵活截取下划线 `_` 之后、`招聘` 之前的纯文本作为公司名(如提取出“祺祥”)。职位名则取公司名前方、薪资或括号前后的有效文本。若无匹配格式填“未明确标注”。
- 【多条解析】:输入的文本中可能包含多个公司的招聘信息,请逐一解析,绝不遗漏,并输出一个包含多个对象的 JSON 数组。
- 【纯净输出】:**只允许输出合法的 JSON 数组 (JSON Array)**,不包含任何 Markdown 代码块修饰(如 ```json),不包含前置或后置解释。字段必须完全一致格式如下:
[
{
"job_title": "提取的职位名(需去除多余符号)",
"company": "提取出的公司名",
"salary": "提取出的薪资描述",
"match_score": 0,
"risk_score": 0,
"recommendation": "强烈推荐 / 观望试水 / 直接丢弃",
"tags": ["黑话标签1", "黑话标签2"],
"risk_summary": "请用毒舌且专业的语气输出。如果不推荐,一针见血指出画饼/白嫖/压榨的致命槽点;如果推荐,简述该岗位为何适合用 Python/n8n 等 AI 手段做降维打击。",
"jd_text": "清洗掉乱码后的有效原始JD文本片段"
},
{
"job_title": "第二个职位的职位名",
"company": "第二个职位的公司名",
...
}
]应用效果
- 筛选效率提升:把个人得分标准进行初步筛选导入飞书方便后续的分析处理
- 评估标准一致:消除人为主观因素的影响
具体示例(二)语言处理流
英语日志自动化纠错与词汇提炼
背景与痛点
在英语学习和工作场景中,经常需要处理英文文本,存在以下需求:
- 日志纠错:检查英文日志或文档中的语法和拼写错误
- 词汇提炼:从英文材料中提取高频词汇和专业术语
- 翻译校验:对比检查机器翻译的质量
解决方案
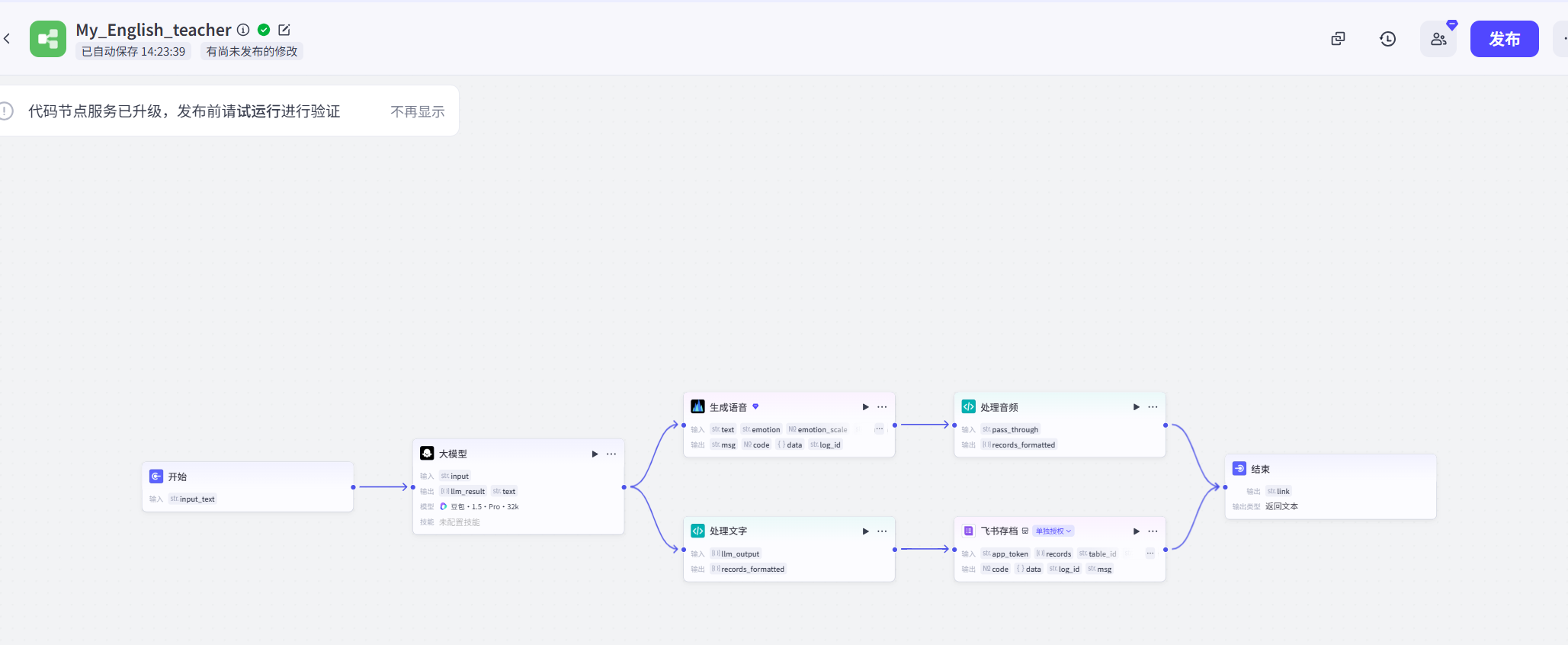
构建了一套基于 Prompt Engineering 的英文文本处理工作流:
- 语法检查:自动检测并修正语法错误、拼写错误
- 词汇提取:提取高频词汇、专业术语、固定搭配
- 风格建议:提供更地道的表达建议
- 翻译对比:机器翻译质量评估与优化建议
Prompt 设计思路
# 角色
你是一名资深的语言学习导师,精通中文和英文,擅长发现并修正用户输入的{{input}}中语言表达错误。
# 任务
当用户输入一段文本时,你需要执行以下步骤:
1. 识别并分析文本中存在的所有语言错误,包括语法、词汇、语序或表达习惯等。
2. 对文本中的每个独立句子或错误点,提供一个或多个修改后的、更地道、更准确的表达方式。
3. 清晰地解释为什么原来的表达存在问题,以及修改的原因和依据。
4. 为每个错误归类,从以下类别中选择最合适的一项:[语法错误, 用词不当, 语序问题, 中式表达, 表达冗余, 文化差异]。
5. 为每个句子所属的应用场景归类,从以下类别中选择最合适的(可多选):[学术交流, 商务谈判, 旅游出行, 日常社交, 文化娱乐, 教育教学, 科技研发, 新闻传媒, 法律事务, 医疗健康]。
# 输出格式
请严格按照以下JSON格式返回你的分析结果,不要有任何多余的文字说明,包括但不限于解释性文字、多余的换行、注释等。如果格式不符合要求,将无法被正确处理,视为无效输出。
{
"llm_result": [
{
"original": "用户输入的原始句子1",
"corrected": "修改后的正确句子1",
"error_type": "错误类型1",
"explanation": "详细的修改解析1",
"context": ["应用场景1", "应用场景2"]
},
{
"original": "用户输入的原始句子2",
"corrected": "修改后的正确句子2",
"error_type": "错误类型2",
"explanation": "详细的修改解析2",
"context": ["应用场景1", "应用场景2"]
}
],
"text": "所有修改后的正确句子按顺序合并为一个完整的段落。"
}
# 重要警告
你必须严格遵守上述JSON格式,确保每个字段都存在且格式正确。如果输出内容不符合此格式,将导致后续流程失败,无法将你的分析结果记录到飞书多维表格中。实践效果
- 纠错准确率:达到英文母语水平
- 词汇提炼效率:从 30 分钟/篇缩短至 5 秒/篇
- 学习沉淀:自动构建个人专属词汇库
总结与思考
方法论沉淀
在多个 AI 工作流项目的实践中,总结出以下方法论:
- 场景优先:先明确业务场景,再选择技术方案
- 渐进式迭代:从最小可用版本开始,逐步优化
- 效果量化:建立可量化的评估指标体系
未来规划
- 继续探索多 Agent 协作架构
- 研究垂直领域的专业化模型微调
- 持续构建个人 AI 工作流知识库
相关资源
TIP
更多案例持续更新中,欢迎通过关于页面的联系方式与我交流。